Azure Data Factory
Azure Data Factory is a data-integration service based on the Cloud that allows us to create data-driven workflows in the cloud for orchestrating and automating data movement and data transformation. Data Factory is a perfect ETL tool on Cloud. Data Factory is designed to deliver extraction, transformation, and loading processes within the cloud. The ETL process generally involves four steps:
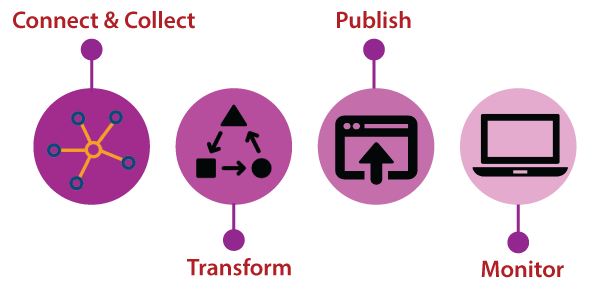
- Connect & Collect: We can use the copy activity in a data pipeline to move data from both on-premises and cloud source data stores.
- Transform: Once the data is present in a centralized data store in the cloud, process or transform the collected data by using compute services such as HDInsight Hadoop, Spark, Data Lake Analytics, and Machine Learning.
- Publish: After the raw data is refined into a business-ready consumable form, it loads the data into Azure Data Warehouse, Azure SQL Database, and Azure Cosmos DB, etc.
- Monitor: Azure Data Factory has built-in support for pipeline monitoring via Azure Monitor, API, PowerShell, Log Analytics, and health panels on the Azure portal.
Components of Data Factory
Data Factory is composed of four key elements. All these components work together to provide the platform on which you can form a data-driven workflow with the structure to move and transform the data.
- Pipeline: A data factory can have one or more pipelines. It is a logical grouping of activities that perform a unit of work. The activities in a pipeline perform the task altogether. For example - a pipeline can contain a group of activities that ingests data from an Azure blob and then runs a Hive query on an HDInsight cluster to partition the data.
- Activity: It represents a processing step in a pipeline. For example - we might use a copy activity to copy data from one data store to another data store.
- Datasets: It represents data structures within the data stores, which point to or reference the data we want to use in our activities as I/O.
- Linked Services: It is like connection strings, which define the connection information needed for Data Factory to connect to external resources. A Linked service can be a data store and compute resource. Linked service can be a link to a data store, or a computer resource also.
- Triggers: It represents the unit of processing that determines when a pipeline execution needs to be disabled. We can also schedule these activities to be performed at some point in time, and we can use the trigger to disable an activity.
- Control flow: It is an orchestration of pipeline activities that include chaining activities in a sequence, branching, defining parameters at the pipeline level, and passing arguments while invoking the pipeline on-demand or from a trigger. We can use control flow to sequence certain activities and also define what parameters need to be passed for each of the activities.
Creating Azure Data-Factory using the Azure portal
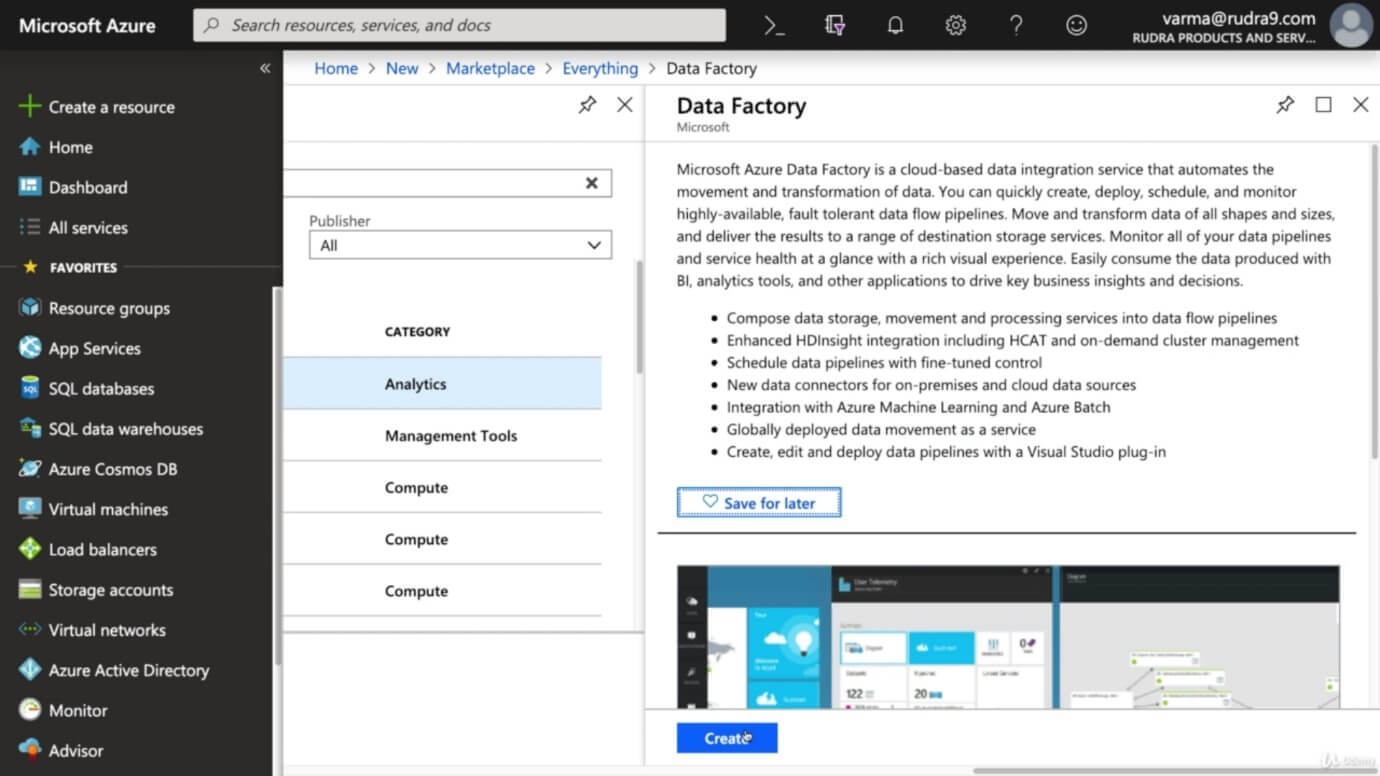
Step 1: Click on create a resource and search for Data Factory then click on create.
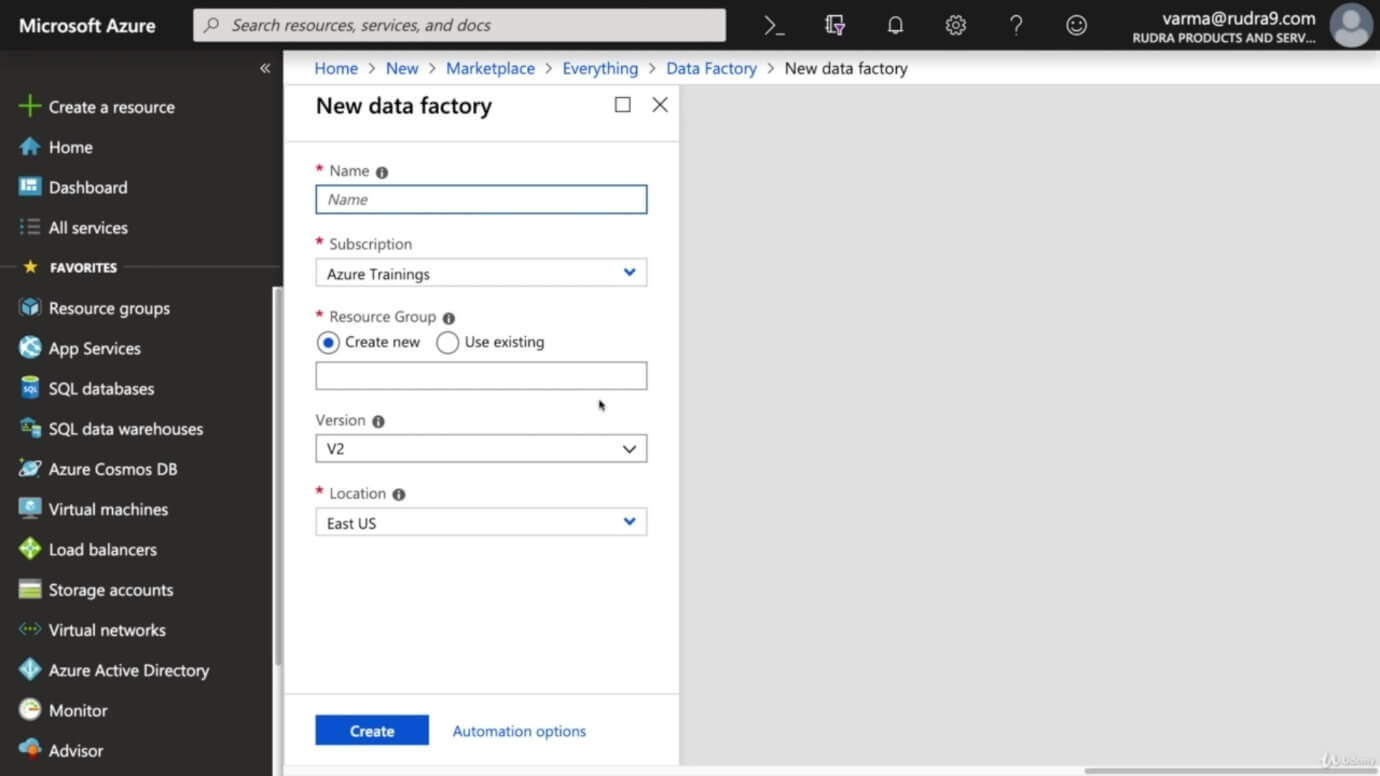
Step 2: Provide a name for your data factory, select the resource group, and select the location where you want to deploy your data factory and the version.
Step 3: After filling all the details, click on create.
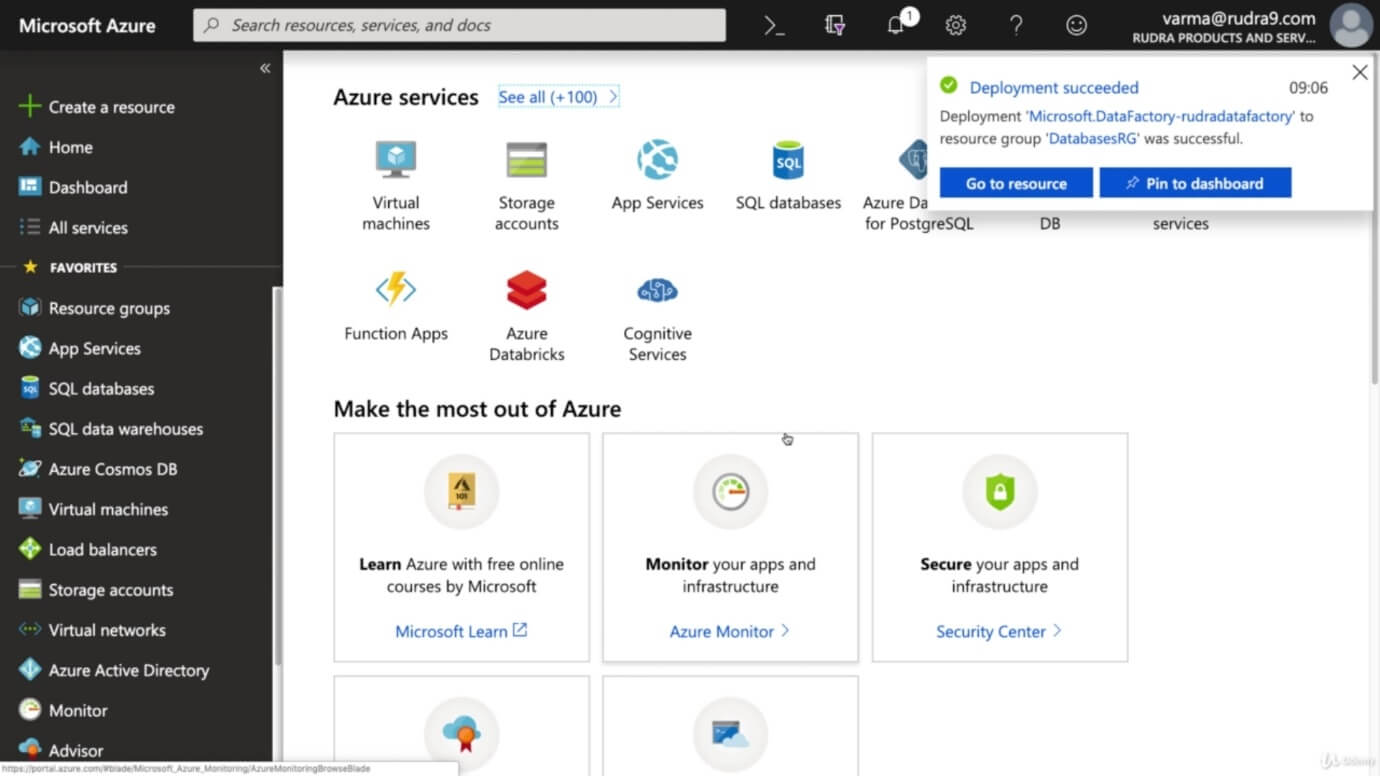
The Azure Data Factory completely had a different portal, as shown in the following figure.
